One of the hardest tasks I encountered during this push was making sure the links at the bottom of each post pointed to its chronological neighbors. It may seem minor at first but completing this would mark the first true advantage over the Wayback Machine from and end user’s perspective. Notice how when you visit an archived blogger webpage on Archive.org and want to read the previous or next set of posts you are met with essentially a 404.
To be clear, when you are viewing an individual post and click on a link to go forward or backward you will not have a problem. This is because Blogger specifically wrote the URL for next post with its title in the link (e.g. http://www.edward.p101/2010/06/celestia_25.html). When viewing a list of posts such as those aggregated by label, time, or text search the link will instead be a query string (e.g. http://edward.p101/search/label/Wizard101?updated-max=2020-04-26T12:00:00&max-results=5). The Wayback Machine doesn’t like saving pages that have query strings because there is the possibility of infinite combinations for every single webpage. There is a grand total of two captures containing a query string so, unless you specifically want the five posts created between July 25-30, 2018, you are out of luck.

I considered creating a new way to control for which results show up on list pages but I decided to keep my rehosting to be true to the original source. The way Blogger handles lists is hard to implement but it is actually pretty smart. You only need two pieces of information: the datetime of the next newest post and the total number of posts to show (plus a label or search term if we’re getting fancy). The hardest part about this system is getting the date of the next post. It cannot be hardcoded in the PHP file or the database itself because there is no guarantee that the next post fits the same criterion of the list (i.e. it has a different label when searching for posts with a specific label).
Here is the logic I settled on.

This is the easy part. If the content type being displayed is a post, set the newer and older links to be the chronologically adjacent posts. I hardcoded the numbers of the first and last posts since Edward himself is unlikely to make any more posts. If the current post is the first or last one then there shouldn’t be a newer or older post, respectively. I save that as a flag to use later on. When the post is not one of these edge cases then query the database to get the posts whose numbers are either one above or one below that of the current post. Because only the URL is needed this is the only field I request.

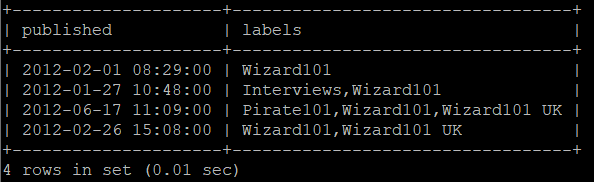
If the type of content is a list of posts then I set up for the more complex queries. The published field referenced above is the datetime that the post was, well, published. From here on out there will be a lot of prepared statements. The parameters below each query statement just substitute each value in to its corresponding ? placeholder to prevent SQL injection attacks. This next if statement is nested within the belly of the above elseif.

This is the next easiest case; there is no label. Getting the next oldest post is fairly simple, just query for the next published date using the less-than operator and make sure that it is sorted in descending order. To get the next newer post is a bit of trick. If you repeated the first step and just flip the less-than sign you get the five (or whatever number) newest posts every single time. To get around this I made a subquery. The inside query gets the five newer posts but in the wrong order. Then the outside query reverses the order and grabs the one on top. A generic label after the subquery is required and just gives a name to the initially returned results.

When there is a label selected there is a bit more logic required. The LIKE statements within the parentheses is to make sure that the current label is included in a posts’ attached labels. In the database each post has its list of labels separated by commas. Each label can either be the first, last, in the middle somewhere, or the only one. Each of these scenarios puts commas in different places so it is important to be vigilant in checking all four cases (before, after, both, or none). If only some cases are checked then this could cause problems, most obviously where the Wizard101 and Wizard101 UK tags intersect. The % are wildcards meaning that any number of characters can be substituted it its place to help with matching, and they are concatenated with the current label.
After constructing a query to get the chronologically adjacent post dates the next step is to execute them. Below is the sequence of steps to do this (for the older post, but works for both). As I mentioned earlier, these are prepared statements so there are two lines to send the query to database. Once it is prepared and executed then the results can be fetched. If there are no results that fit the query then again we indicate that this is the oldest or newest post. Outside of these two cases, the URL is formatted to then be put in the link. When there is a label involved this is done by taking the current webpage address, $_SERVER["REQUEST_URL"], and substituting its query string with the one which returns the neighboring post. Otherwise, in the case of lists of posts based on a year of month, we want to get rid of the year/month from the URL so that lists can span multiple years/months if necessary. This entire block of code is repeated for newer posts as well with the relevant variables substituted.

The last step of this process is to actually put the constructed link into the webpage. Remember that, even though this code will appear on every single page, links should only appear to the user when they are viewing a post which is not the oldest or newest. The logic below takes care of that.
