In the 2022 recap post I made earlier this month one of the goals I set was to scrape Google+ for its Pirate101 data. This has been a lofty goal of mine since I first started this projected in August 2021 and, since this is my last semester with the essentially unlimited bandwidth of my university, I thought I would take a stab at it.
Google+ started back in 2011, right before the advent of Pirate101. People could make posts on their own personal page or to a community of their choice. Others could then comment on these posts and drive engagement. The whole concept overlaps a lot with Blogger, also owned by Google, so it is not too surprising that the plug was pulled. In Google+’s hasty dismemberment in Spring 2019 the Archive Team attempted to rescue as much data as it could. After the fact this data was uploaded to the Internet Archive as a collection of 1.1 petabytes of data split into 33,033 entries. Each entry is further split into 9 files of differing size and composition.
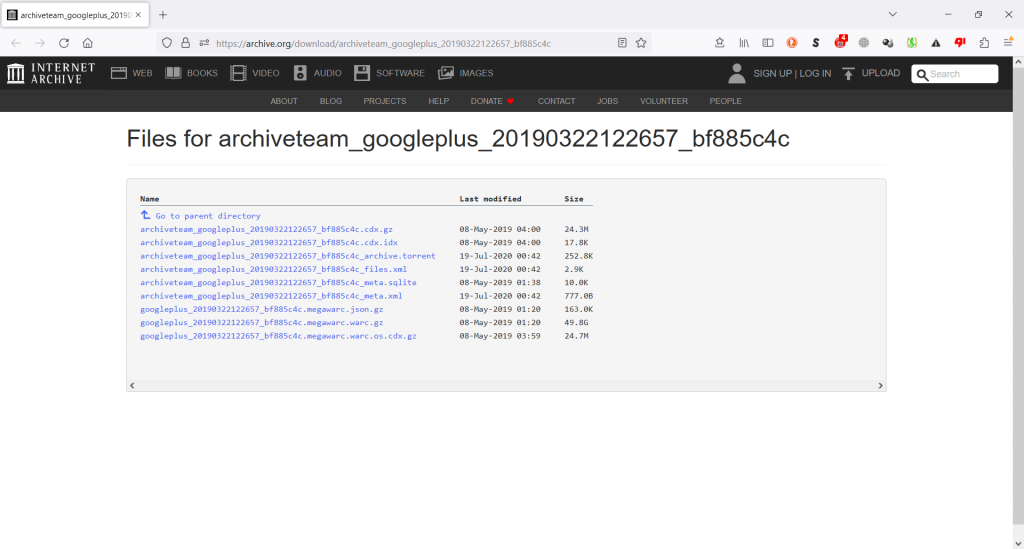
The most approachable file is the one ending in .cdx.idx. This one is a list of web pages and where the are located in the corresponding .cdx.gz file. The first column is a reverse of the url (plus.google.com/123456789), then a timestamp, the file name where the record in question is located, and finally two offset numbers.
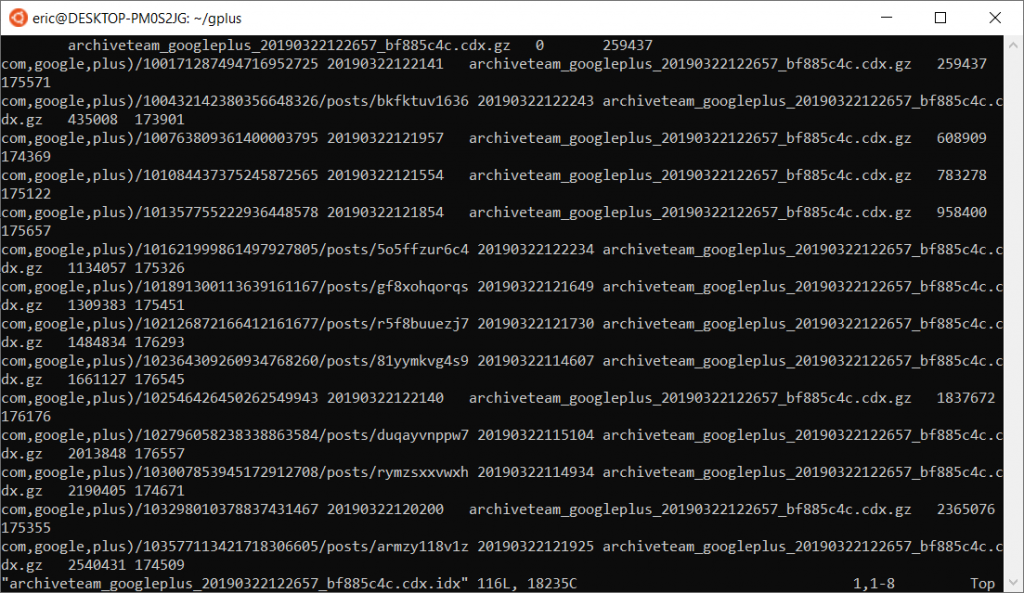
I wrote a basic python script to grab each and every one of these files from the Internet archive and check line-by-line for the specific Google+ id (in Pirate101’s case 107874705249222268208). I’ll post the script somewhere in its entirety, but the gist of the thought process is as follows:
- Compile a list of all the Collection entries and save it to a file
- Iterate through each collection name as saved
- Use wget to download the .cdx.idx file
- Iterate through each line in the file and look for the Google+ id
- Repeat until all files have been checked.
I have some special logic to save the current file being checked in the event that the program must be stopped so that it can be started again in the same place in the future. I also added some snazzy terminal output and a file to save any lines which contain the special ID. After each file was finished being checked I had the script delete it to save some room on my C: drive (where WSL running the script is installed to).
This script operated surprisingly quickly and executed through to completion (33,033 files) over one night. Unfortunately I didn’t have any hits on the Google+ id I was looking for, but I shouldn’t be so surprised. I’m not actually sure what I was checking for with this script because the .cdx.gz file in each collection is approximately only 25 MB in each collection, much less than it would take to store the ~20,000 web pages listed in the .cdx.idx file.
This is the point where I started to re-evaluate the choices I had made. I scraped the .cdx.idx files because they were easy. All of the random test links from these files I pasted into the Wayback Machine actually resolved to a valid page. The first link in the previous screen capture leads to this page in the Wayback Machine, meaning that it was successfully captured, even if there is no meaningful content. If that’s the case, then why weren’t there any links to the P101 account?
As I dug further into what little documentation there is concerning the Google+ archival effort, it turns out that the data has already been ingested into the Wayback Machine. When visiting random Google+ archived pages that I did not stumble upon during my primitive search efforts, I noticed that every single capture from late March and early April 2019 were branded “Google Plus or Minus” at the top. This is an indicator that the data was initially fetched as part of the Archive Team effort and that after some time had passed it had been incorporated into the Wayback Machine.
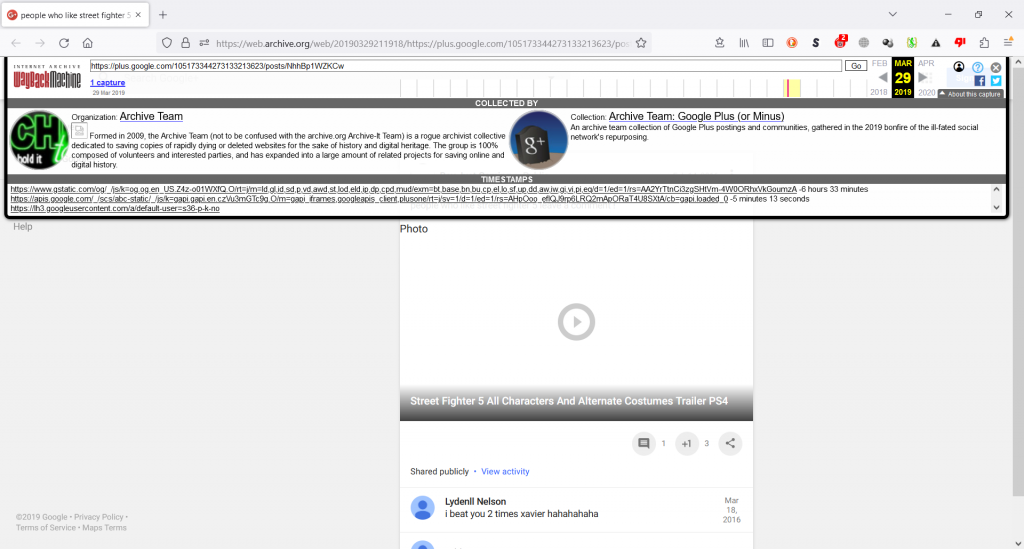
Boy Just Gaming is a user who commented frequently on P101 posts and one of his own posts is shown in the screenshot above. He has 80 posts that were grabbed in the same time frame as the Google Plus or Minus campaign. If that’s the case, then you’d think that there would be at ton of Pirate 101 Google+ pages saved in the same manner. Unfortunately that is not the case. Instead there is only one page that was captured between March-April 2019. Furthermore, all of the archived pages are from 2013, a far cry away from what the P101 Google+ community looked like in its more recent life and lacking in 3 years of content (most recent post was in 2016).
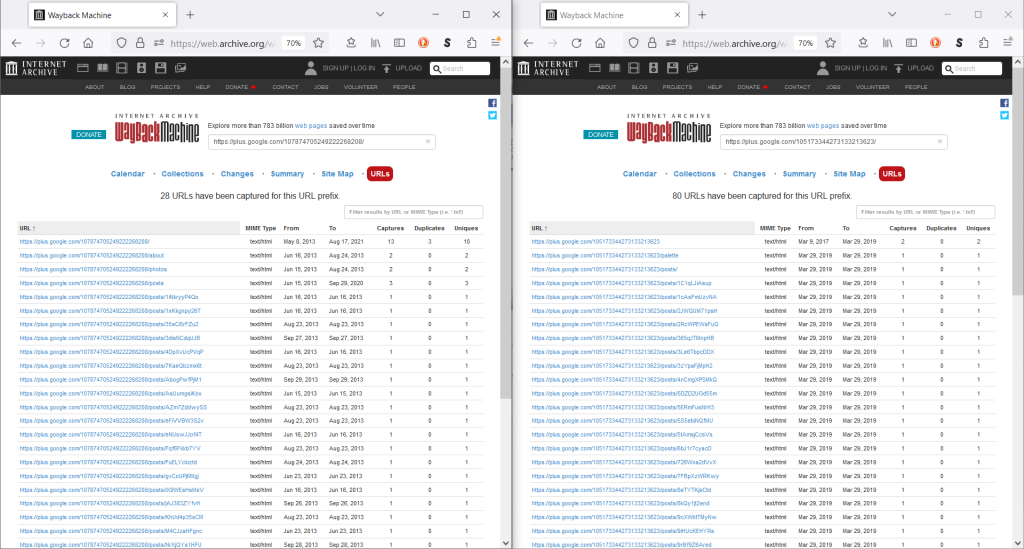
To make things worse, the Archive Team page on Google+ lists the project as “Profiles: Saved! (98.6%)”. This and the evidence above are pointed indicators that the Pirate101 Google+ page slipped through the cracks. Back in Spring 2019 I was busy finishing out my last semester of high school and didn’t think to keep track of or contribute to the effort to archive those Google+ sites which would come to mean so much to me after their loss.
But this month’s work/research is not all doom and gloom. There are still at least 28 posts for which I can create a .p101 site that displays this information as it would have been seen four years ago. Also, going back to the opening paragraph of this post, I plan on using my university’s internet connection to check as much of the data as possible myself. I have only downloaded one of the hefty 50 GB files which contain the actual HTML data, so I only have 33,032 to go. Who knows, maybe I’ll get lucky and the Internet Archive simply forgot to merge a few Google+ posts into the Wayback Machine.