As I dug through my scraping logs, I encountered something I didn’t want to see: lots of logged errors. This is particularly fitting because I created the auto-scraping mechanism last March, approximately one year ago.
Final Bastion is the site in question and the errors had existed more or less since the beginning of the year. According to my logs, the problems began on January 1st and continued for four days. I cannot remember if I did something to stop this or if it worked itself out on its own. My scraper then ran without issue until February 21st, when the problems began again. I was hoping the issue would once again go away without my intervention, but that’s not what happened.
Yesterday, after 19 days of my scraper failing to check if Final Bastion had made any new posts I decided to investigate the problem. I started by copying my scraping script and tearing out all of the parts that update the database and loop through each site. I then printed the values of a few variables immediately before the problematic section. The result: a 403 Access Denied error.
This is a strange error to get. I wasn’t attempting to visit a strange page or one that I wouldn’t have access to. The web server was saying that I did not have the proper credentials to visit http://www.finalbastion.p101. Ya know, the homepage of the website. At first I thought that the people behind Final Bastion changed their file structure or domain name, but when I opened the very same page on my laptop there was no issue.
To see if this was a problem with my server or the Python code, I used a few low-level Linux utilities. The first one was ping, a CLI tool to see if a server responds to requests for acknowledgement.
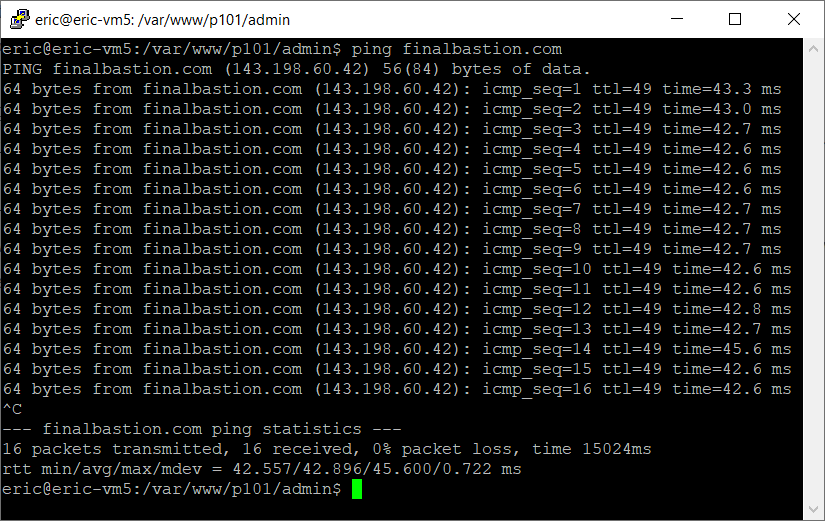
This test showed that the server referred to by finalbastion.com exists and responds to my server’s message asking if it can be heard. The next test is wget. I have used wget before in attempt to scrape P101 Central, but it can also be used to grab a single webpage.
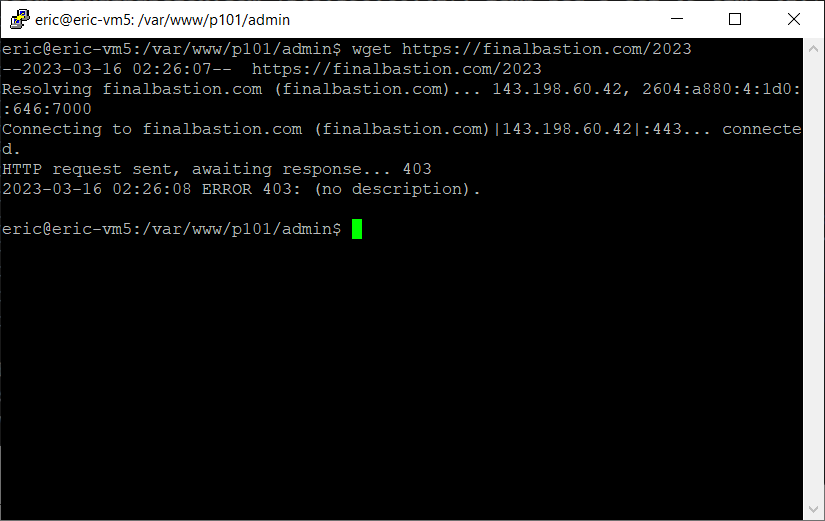
This doesn’t really help much, but it shows that the problem is not isolated to the Python library I use to scrape websites. With the little information I have been able to gather I cannot think of any other reason for the 403 errors other than being IP banned. This means that the server hosting Final Bastion’s content is refusing to serve the webpage.
The best way to try to get unbanned is by waiting it out. I figure that if I only attempt to reach the server once a month instead of every single day I might be able to get webpages instead of 403 errors. The easiest way to do this is by having one more conditional in my scraping code. If the site to scrape is Final Bastion and the day-of-month is 1, try to visit it. Any other day this step will be bypassed.
if "spiralradio" in site_url:
api = requests.get(site_url+"/?m="+str(cur_year))
elif "finalbastion" in site_url and datetime.datetime.now().day != 1:
#attempt to wait out ipban
return("ignore",0)
else:
api = requests.get(site_url+"/"+str(cur_year))
I will check back in on April 1st to see if my scrape attempt works. If not, I will likely have to increase the time between scrapes.