Now that we have found and made a list of all the Pirate fan sites, it’s time to start archiving them. This process can be concurrent with the previous one, and every time I found a new site I would enter it into the spread sheet and then immediately download it. There are two ways to download these sites, depending on whether they are still natively accessible or not.
Live Sites – WinHTTrack
HTTrack (or WinHTTrack for use on Windows systems) is open source software specifically built to download entire websites. It is older than I am and essentially the standard tool for doing this sort of thing. I have used it in the past and definitely recommend it whenever you want to save a snapshot of a website for offline viewing or if you are afraid it will be pulled.
Upon launching the program you are greeted with a welcome screen. To create a new website mirror you simply enter a name for the project, the URL you want to download from, and start. There are some settings you can mess with to exclude some things or include others, but it really is that easy.
When it’s done it makes a folder containing all of the webpages that were available on the domain you entered. If an external script was called on one of the pages, a folder for that website was created, too. The finished result is a copy of the entire website with relative links so that when you click on one it does not actually take you to the source website. I wrote a much more in-depth explanation of this in the post about restructuring the default directory system a few weeks ago.
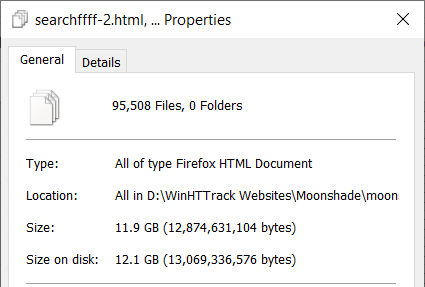
Using WinHTTrack will give you the most comprehensive copy outside of someone sending you the actual website files. With that being said, it is not perfect. Most websites are dynamic, meaning they have content that changes depending on user input. Javascript is downloaded in the program because it runs on the client device but PHP cannot be downloaded: it runs server-side. WinHTTrack does its best to handle this gap by downloading many different iterations of this dynamic content. For example, Blogger websites have the ability to access older content on the main page by clicking “Older Posts” at the bottom. You never leave the search.php webpage but each time you click the button you are shown different content. In the extreme case of Paige’s Page which hosts over ten years of content, WinHTTrack saved over 95,000 different copies of search.php totaling approximately 12 GB. This is a massive waste of space compared to a proper setup using database queries, but at least it’s something.
Dead Sites – Wayback Machine Downloader
Downloading dead websites feels more like archeology than proper archival work. Because these sites are no longer available natively on the internet we must rely on the Wayback Machine. After some searching I found a few commercial services that restore websites from the Wayback Machine but I’m both cheap and supportive of open source software. That left me with Hartator’s Wayback Machine Downloader on Github. The installation process was a bit more in-depth than simply running an EXE like WinHTTrack. I do not remember exactly the steps I took to install it, but it did require Ruby which I recall was unpleasant to get working.
Wayback Machine Downloader is a command line tool which I think tends to scare people. Assuming you got Ruby installed it really isn’t hard to use. There are many different flags you can use to tailor the download but the only one I used was -t to set an upper limit of the date a webpage was captured. This is so you can exclude recent captures that don’t actually contain the content you are looking for (redirects, shutting down notices, parked domains, etc.) The general format of a download is as follows:
wayback_machine_downloader http://www.duelist.p101 -t 20181009
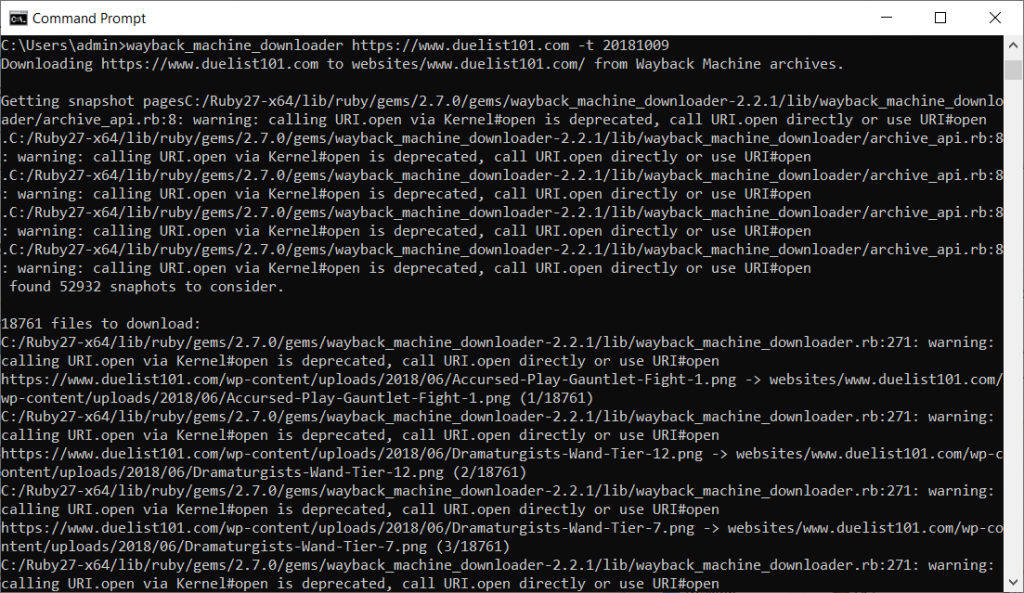
There are lots of warnings thrown but these can just be ignored. In the case of Duelist101 there are 18,761 files available to download. Seeing a number this high is fantastic and means that the final mirror should be mostly usable. An unfortunate number of sites have very few captures (some as few as single-digits) and this means that it is practically useless; what is the point of having a mirror if every single link on the main page is dead?
An additional step that must be completed after using the Wayback Machine Downloader is to update all of the internal links. The program downloads raw HTML files and does not go through the trouble of reformatting everything to work nicely. Whereas you can browse WinHTTrack sites locally on your computer, links on these pages still go to their original destination which no longer exists. We must therefore replace all of the duelist.p101/whatever.html calls to duelist.p101/whatever.html. After uploading the files to my web server I ran the following command from a Stack Overflow thread:
find /home/eric/www.duelist.p101/ ( -type d -name .git -prune ) -o -type f -print0 | xargs -0 sed -i 's/duelist101\.com/duelist.p101/g'
To be honest, I am not sure what everything in this statement means. At a high level it is replacing the string duelist.p101 with duelist.p101 for every file in the www.duelist.p101 directory using regular expressions (regex). This command must be run in a Linux environment such as the Ubuntu server I use to host everything, not the Windows command prompt that was used to launch Wayback Machine Downloader.
I always encourage everyone to try stuff on their own, but this step probably is not necessary unless you intend to host the files on a domain you own. And in that case you would have to replace duelist.p101 with your domain. If your goal is to make a mirror that you can browse on your local machine, you would have to replace both the http:// in the links to C:\path\to\files and the domain to the new directory name. I have no idea how to write good regular expressions so you’re on your own for this one!