It’s bit late to start doing this but here goes.
Like so many other content providing services (recently Twitter and Imgur), Reddit recently made the decision to stop offering its powerful free API. It then went a step further and demanded that services which publicly hosted searchable archives stop providing access. A third party service called Pushshift was the most public victim of this action and blocked access to its own API of archived Reddit messages in order to comply. This is all on the road to commercialize Reddit before an IPO.
The Pushshift API stopped working on May 19th, so I missed being able to backup r/Pirate101 by a little more than a week. Now things have become much harder. Not impossible, but much less convenient than a simple script.
After some reading I learned that the official Reddit API is still up, but it leaves much to be desired. You can only pull up to 1000 posts at a time and there is not (to my knowledge) a way to grab explicit time intervals. This would make it impossible to iterate through time intervals in order to grab every single post.
I did some more searching and it turns out there are still a few copies floating around of all Reddit submissions and comments through March of this year. My thought process was that I could grab all of this historical data and then use the new gimped API in order to grab the posts that have been made since then. Assuming a liberal 15 posts per day, this should fully cover May and April and consequently no lost data.
The New Data
I’m starting here because it turns out that using the API is surprisingly easy. I found a project on Github called Bulk Reddit Downloader which allows you to download not just the text contents of a Reddit submission but also any attached media. I recently built a new computer which runs Ubuntu, so all of the following commands will likely only work in a Linux environment. I used Windows Subsystem for Linux (WSL) on my old computer to achieve the same functionality.
python3 -m pip install bdfr
I had an issue where the package was not automatically in my computers’ path. This means that my computer would not know where to find it when attempting to run the package so I had to add the following line in my ~/.bashrc file:
export PATH=/home/eric/.local/bin:$PATH
Another issue I ran into was on my first trial run. When the program ran into a video file it failed to download it because of a missing package. I was able to fix this problem by installing ffmpeg.
sudo apt install ffmpeg
Once the package is installed you can then use it directly in the terminal as a command. All of the different options are explained on the projects’ Github page but I only needed a few. The second parameter clone downloads both the text and linked multimedia files. The period places the file in the current directory. Then -s specifies the subreddit to download, and -S sorts it to grab the newest posts (as opposed to most upvoted or controversial).
bdfr clone . -s Pirate101 -S new
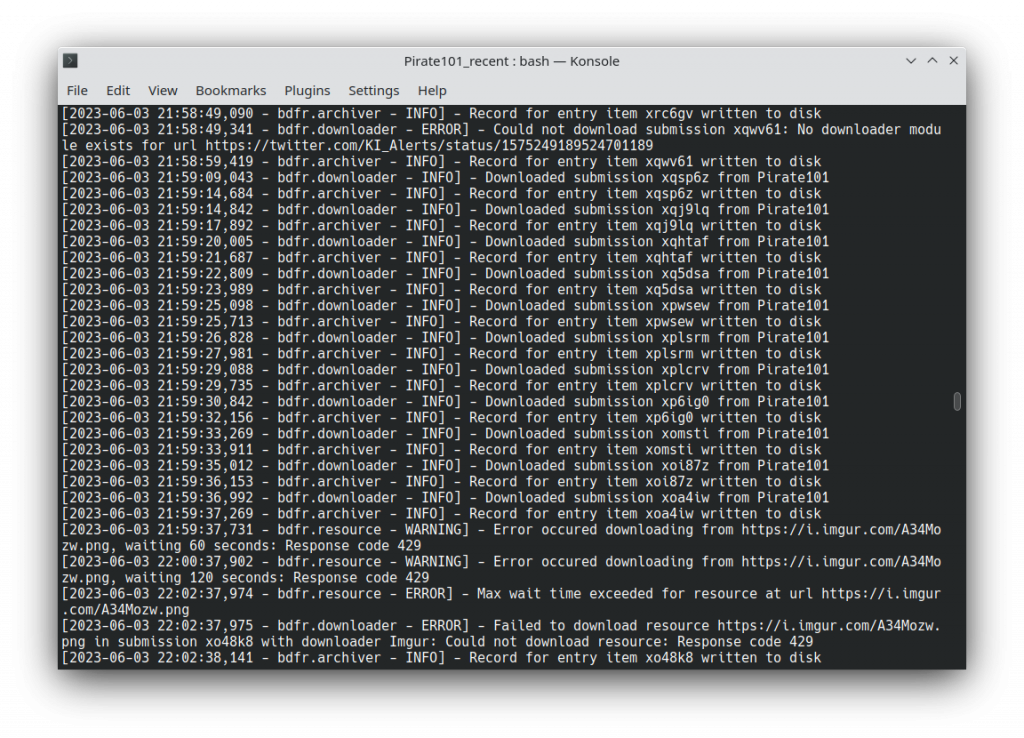
It took over two hours to download everything and left me with 2295 files totaling almost 9 GB. There were a few instances where the program did not know how to download a file from some external resource (the error at the top of the terminal) or specifically Imgur (the bottom error) which recently deleted a ton of its content. I’ll have to manually find these files at some later date, especially when someone makes available an archive of all the deleted Imgur images.
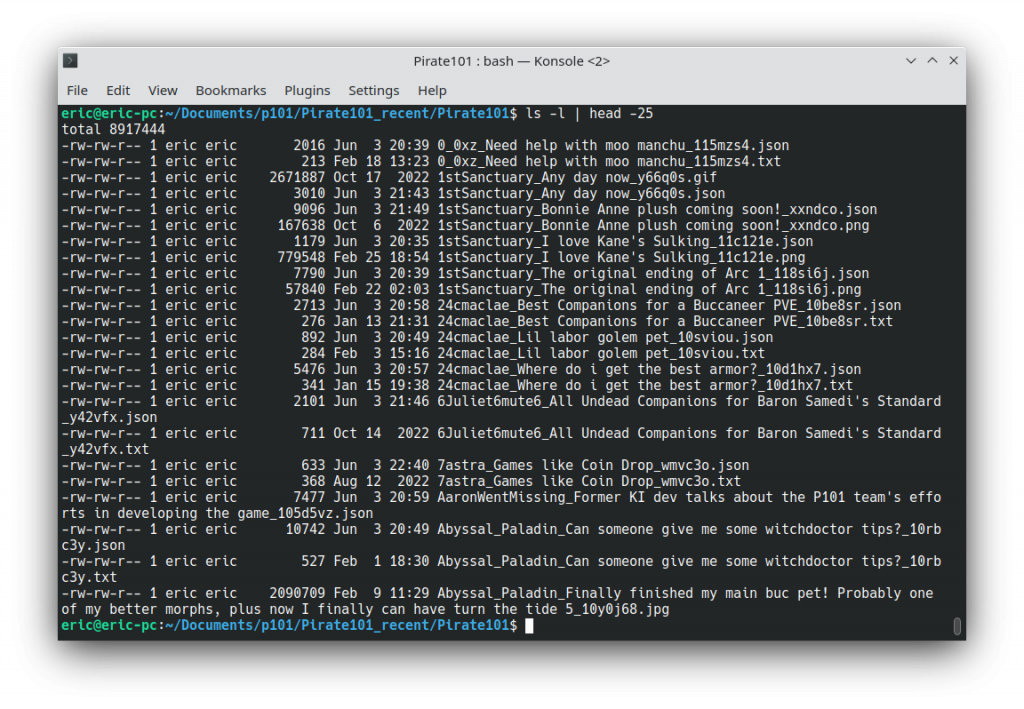
The 1000 posts I was able to download stretched all the way back to July 2022 so I don’t have to worry about submissions that were not captured by either the old or new scrapes. Each JSON file has a modified date of when it was downloaded on to my computer but the media files retain the date of their original posting. Each JSON filename has the author’s name at the beginning and the post ID at the end. Each post has at least two files: the JSON and a TXT file for text posts or the media files for an attached pictures or videos.
The Old Data
It was thankfully not too difficult to find data similar to, if not the same as, the data that Pushshift itself hosted. For each of the top 20,000 most popular Subreddits, The Eye hosts individual files which can be directly downloaded from their site. This would have been hugely helpful if r/Pirate101 was in the top 20,000 but unfortunately it is not.
Downloading
Instead, I have to acquire the full, over 2 TB archive from Academic Torrents. There are two issues here: firstly I just barely have 2 TB storage capacity on my computer and secondly torrenting is a larger headache than regular direct downloads. Torrenting is most often used to share pirated movies and software, so when torrenting you have to be careful that your Internet Service Provider does not think you are breaking the law. Due to the fact that the torrent was from a website that only hosts academic data I was not worried and opted not to use a VPN.
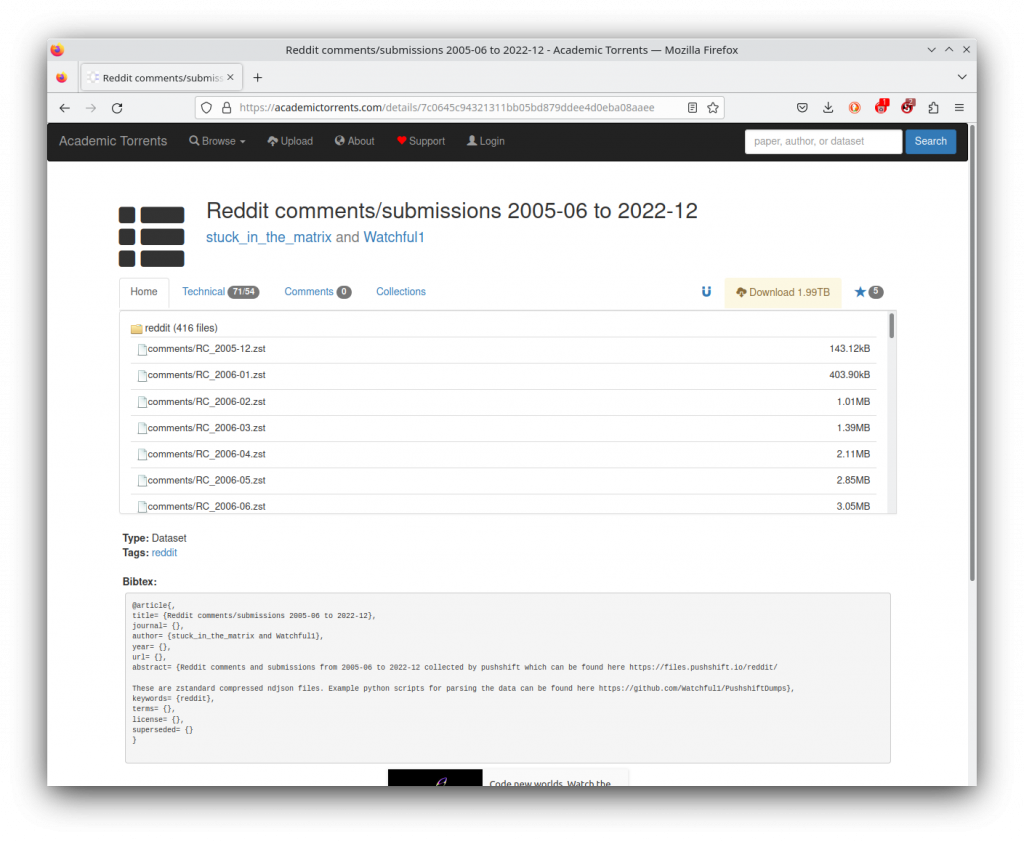
Clicking the “Download 1.99TB” does not download all of the files but instead downloads a 2.3 MB torrent file. Opening the file on my computer causes a window to pop up on my desktop from KTorrent. This is a torrent client that comes pre-installed on the Kubuntu operating system. It works well enough for my purposes so I am going to use it it instead of installing some other program. I opted to only download the archive in one-year chunks so as to not fill up my entire computer’s storage.
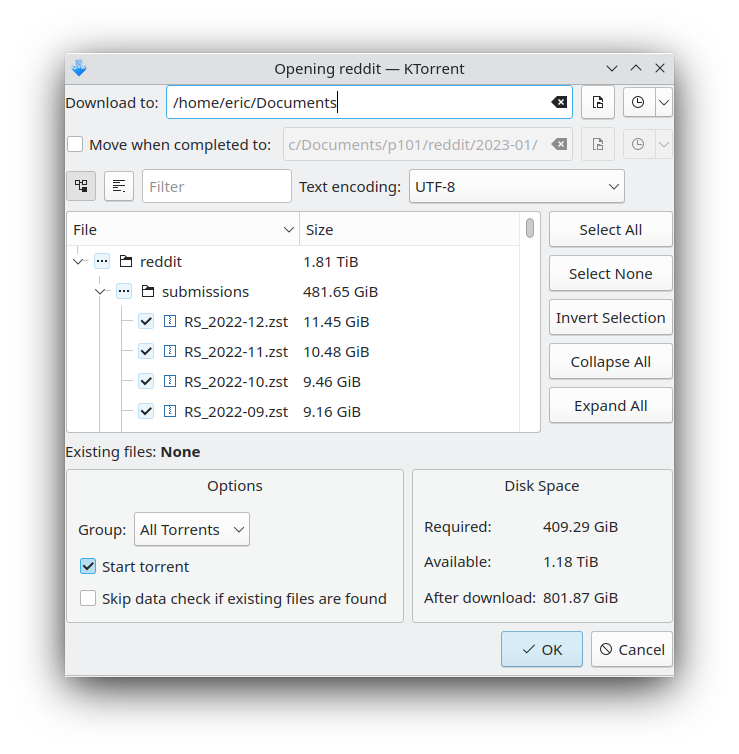
After clicking OK a new window pops up with the current download progress. There is a row for this torrent showing various statistics. Additional torrents would have additional rows. At the bottom is a table pertaining to the currently selected torrent. Each of these rows is a computer somewhere in the world that is sharing the file with me. I am currently downloading from each of these computers (not one centralized server) and uploading to ones that do not yet have the entire set. This allows for surprisingly efficient file downloads and is the same reason for its use with pirated content.
Unzipping
The downloaded files are in a ZST format. This is a lossless compression scheme like ZIP or 7Z that needs to be unzipped. Unzipping creates a new, significantly larger file derived from the compressed one. The way to do this (at least on Linux) is with the zstd command. I had some kind of memory issue but I was able to fix it with the parameter at the end.
zstd -d RS_2023-02.zst --memory=2048MB
The sheer amount of compression that these files have undergone is incredible. Unzipping submissions from February 2023 ballooned the file from 9.3 GB to 127.3 GB for a compression factor of 13.7. Similar results can be said for the comments of the same time period, where they were decompressed from 22.7 GB to 289.9 GB. When done the original file remains and the new decompressed file is created with the same name but lacking the .zst extension.
Extracting Relevant Content
With the monthly content scrapes now decompressed and holding most of my computer’s storage hostage, I now have to extract out only the posts from r/Pirate101. These unzipped files are of the JSON format which makes reading from them fairly easy. I first wrote a Python script and realized just how long this process would take so I opted to touch up on C and write something much faster. I have another post which goes over my process in more depth.
./extract RS_2023-02 c_subs.json
C programs must first be compiled and then can be executed with the ./ operator in front of the filename. For my program I required two input parameters, the location of the file to be scraped and an output file for the extracted data.
Results
This effort took significantly longer that I had anticipated, in the order of a few extra weeks. Between figuring out what the Reddit situation actually entailed, where and how to get the data, actually downloading it (several terabytes), debugging C code, and not to mention my full-time job, I am kind of worn out.
All in all, I have acquired 8.5 GiB of text and media across the 1000 most recent posts from the method described in the New Data section above. In addition to that, I have 186 MiB of post submissions and 537 MiB of comments in a raw JSON API format. This amounts to 5586 posts and 37507 comments from April 2012 until the last ever public Pushshift dump through March 2023. For those of you curious, this is the very first post on r/Pirate101, from April 25th.
Eventually I would like to rehost all of this content in an interactive way similar to what I have done for Edward Lifegem’s Blogger site. But before I can do that, I need to download the attached media from each of the raw JSON posts, something I would like to do soon. Also, because Reddit is keeping a free (but severely limited) public API, I would like to create a scraper that grabs all content on a much more frequent basis to avoid data becoming inaccessible forever.
Lastly, I started work on this effort several weeks ago. I know this post and its accompanying one on efficient coding have been completed a decent chunk of the way through June, but I’m setting their published dates to exactly one month before. This is with the understanding that I will be able to complete another (albeit less involved) effort to be published in June.