This post is going to be short because I had written it in November (currently January 2023) and, after my server instance got deleted, lost all progress. In the grand scheme of things I didn’t learn much so here is the gist.
Last month I created a system to check when a website’s domain would expire. It works how I had intended and notified me that the pirate101central.com domain would expire in a few weeks. I waited this time out expecting the domain to be renewed, but two days before the expiration date I got nervous and started downloading. WinHTTrack is the software I usually use for this, but it was working more slowly than I would have hoped.
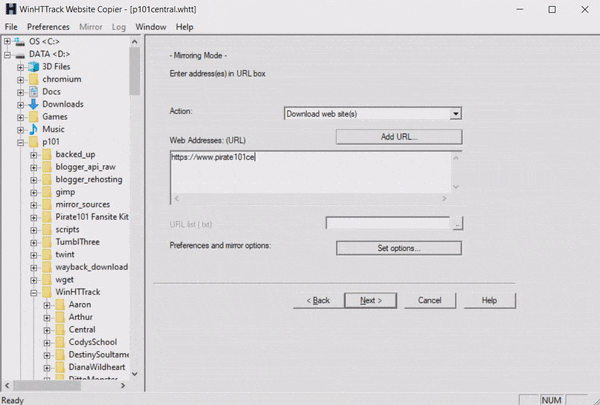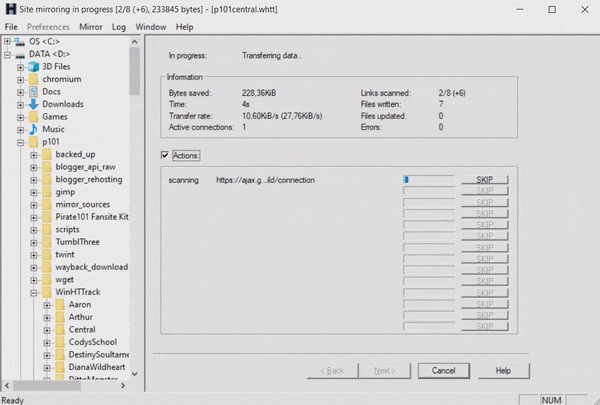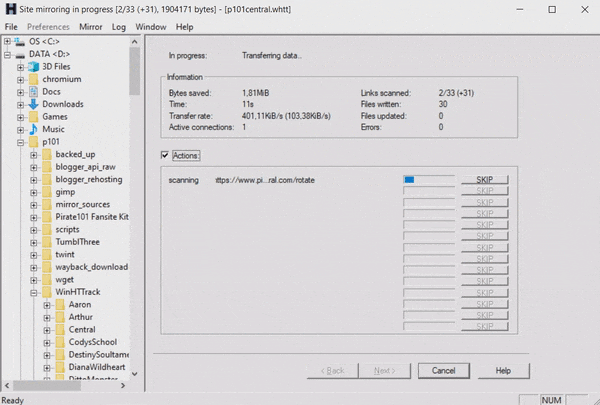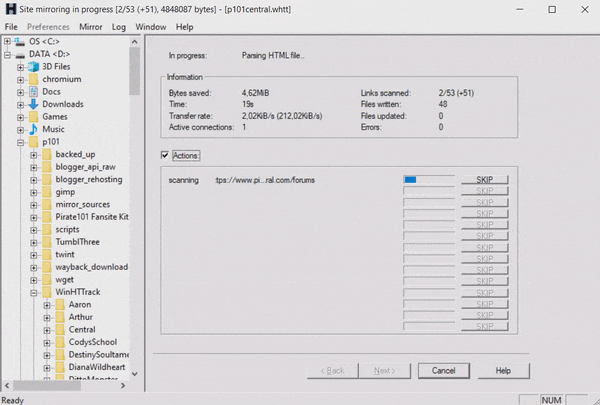
I had heard of using wget to download websites before but never used it in practice. I followed this tutorial to craft a statement to do what I wanted.
wget --mirror --page-requisites --convert-links --adjust-extension --compression=auto --reject-regex "/search|/rss" --no-if-modified-since --no-check-certificate --user-agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:108.0) Gecko/20100101 Firefox/108.0" http://www.central.p101
After pasting this into my Linux terminal it immediately started downloading.
Over the course of two days these two methods came to completion and downloaded a large portion of the website. Due to the vast scope of Pirate101 Central I am not surprised that it didn’t get everything. I would have been more upset if the pirate101central.com domain hadn’t been renewed. Somehow it was renewed the day after it was set to expire. I’m not exactly sure why this happened but I am thankful for it regardless.
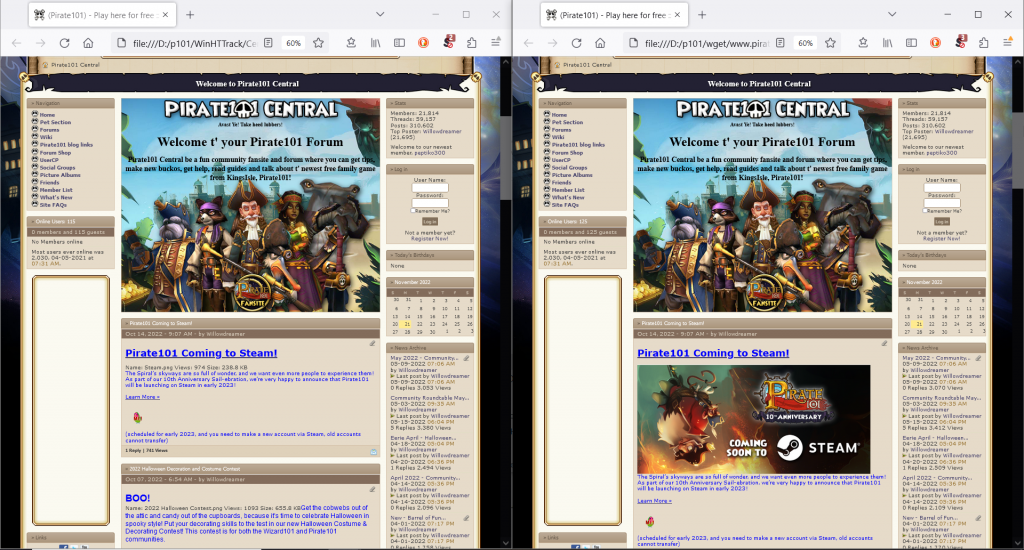
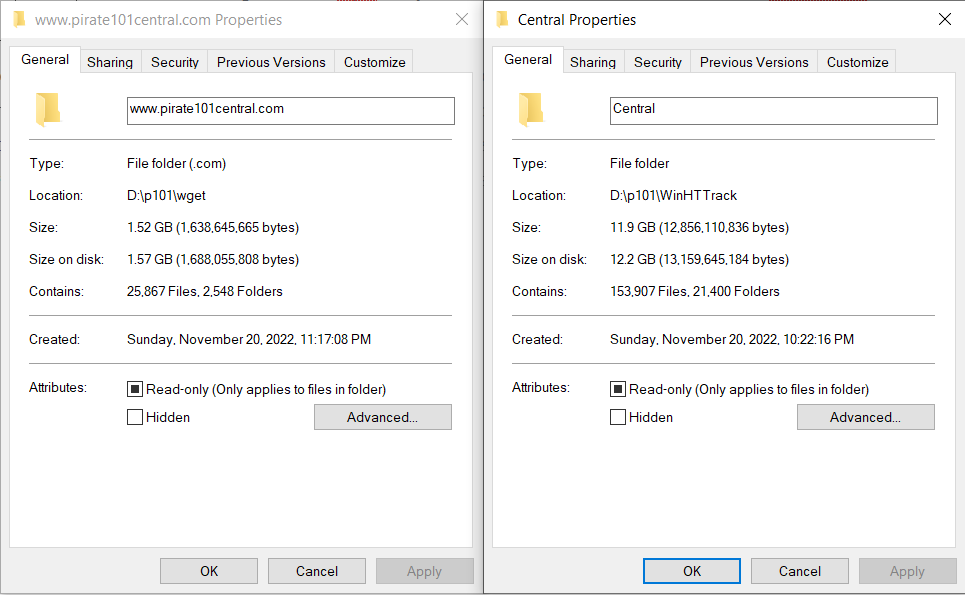
Neither of the site mirrors are perfect, largely due to the scope and complexity of P101 Central. While both processes ran more or less to completion (wget stopped gracefully and WinHTTrack kept crashing after repeatedly being restarted), WinHTTrack grabbed much more data than wget. In the near future I will need to scrape Central using a custom setup that grabs page content instead of the displayed HTML files.