As you can see in the previous post, scraping from the Blogger API only yields the content of the post itself and some related metadata like date and author. In order to make the posts look like they came from the original website the formatting and CSS need to be copied over. You might be saying why not just copy every page from Archive.org instead of scraping form the API. But the beauty of my solution is that the entire rehosted website will be served from a single file. That’s right: 1892 posts, 20 pages, and an infinite number of post lists that can include labels and a configurable number of results all within index.php.
I grabbed the HTML of the homepage by using the same wayback_machine_downloader tool that I mentioned in Archival Process Part 2: Downloading Sites. I used the following command in my Windows terminal:
wayback_machine_downloader http://www.edward.p101 -e
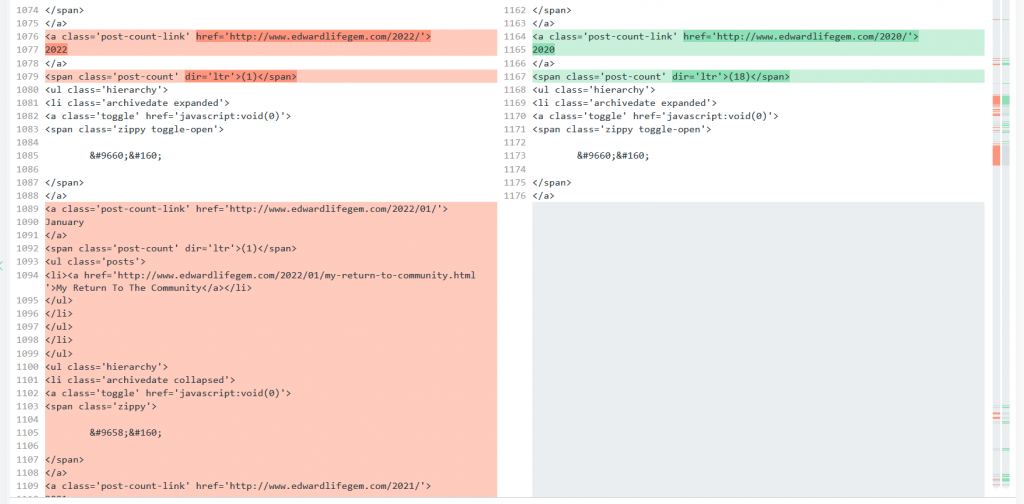
The -e flag is to make sure only the URL provided was downloaded, not the entire website. I then renamed it to index.php. This is the name of the file that is shown when you visit any website’s page at www.example.tld/ without a filename at the end. At this point we have the HTML that renders the homepage but it needs some cleaning up. While it could be left in, the Blogger template is a bit unwieldly and takes up ~550 lines of the 3720 total. We can also remove sections of repeated code that will be automated later. There are about 20 lines dedicated to the page list at the top but this is nothing compared to the more than 2000 lines that create the sidebar for the posts published in each year and month. Keep in mind that all of this HTML will still have to be in the final page shown to the user, but it can be created with code instead of being written discretely.
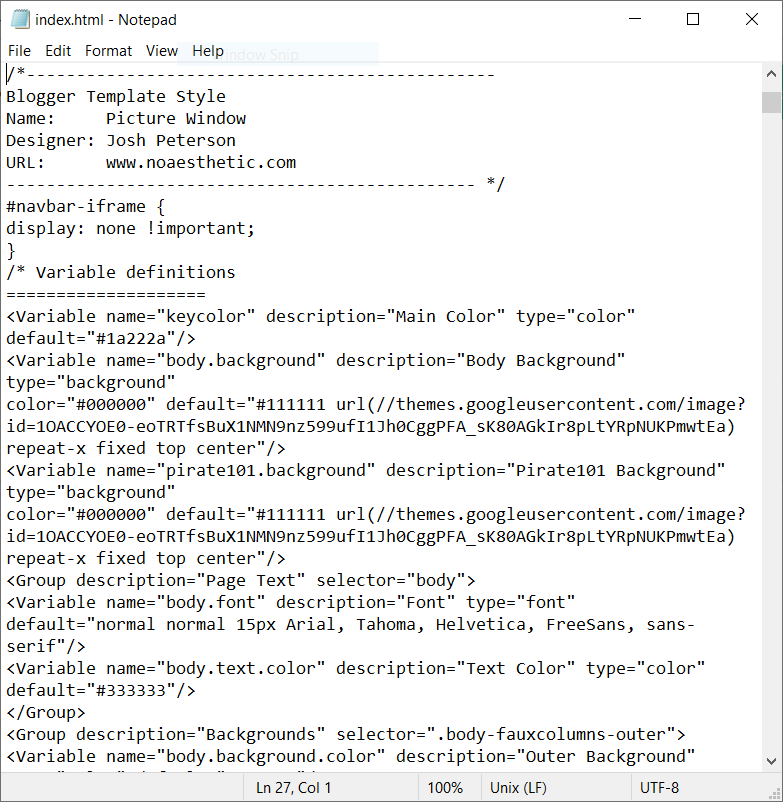
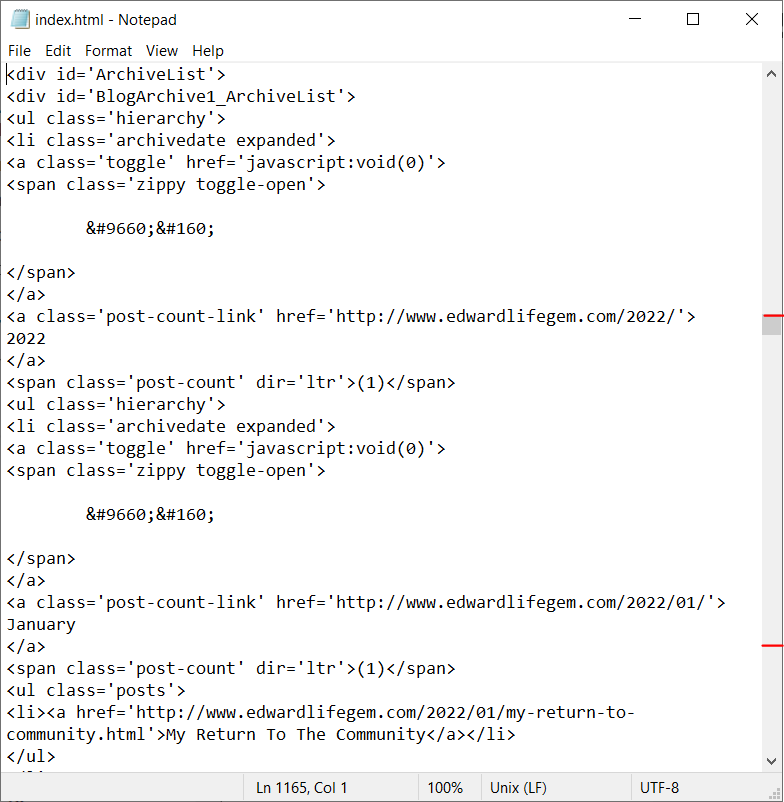
The best way I know of to find the code that must be changed on a per-page or per-post basis is with Diffchecker. I have been using Diffchecker for years to find differences between blocks of code or text and it works phenomenally. Just paste your two pieces of text in the windows and click “Find Difference”. Then on the scroll bar the sections where the two differ are highlighted.
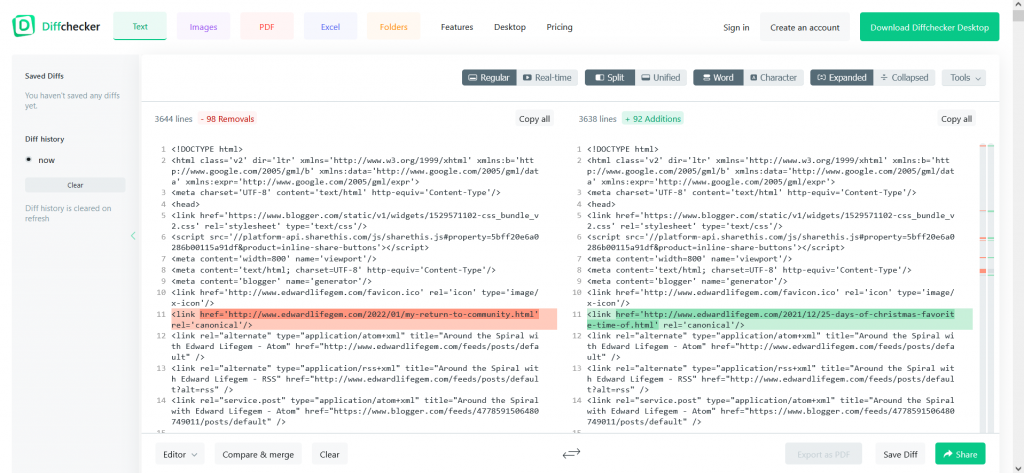
In the above screencap of Diffchecker I have Edward Lifegem’s two latest posts: My Return To The Community and 25 Days Of Christmas – Favorite Time Of Year – Day 3. There is very little variation between the two because they share the same formatting and metadata. If this doesn’t make the reason for serving this content from a database clear, I don’t know what to say. More than 99% of the page content is the same, so why save 1900 copies? The only things that need to change between posts are links and the content of the post itself (the largest block of color on the right).
Pages contain slightly different formatting from posts but they still share a large majority of the same HTML. Below is a comparison between My Return To The Community and Wizard101. The difference is not significant enough to justify pages having their own index.php. In fact, the largest difference between pages and posts is the archive menu displaying a yearly/monthly summary as opposed to the actual authored content of each.